


文章详情

就像Openai拥有Chatgpt聊天机器人一样,DeepSeek也具有类似的聊天机器人,它带有两种型号: DeepSeek-V3和DeepSeek-R1 。 DeepSeek-V3是...
2025-04-03 04:00:02
文章详情介绍
就像Openai拥有Chatgpt聊天机器人一样,DeepSeek也具有类似的聊天机器人,它带有两种型号: DeepSeek-V3和DeepSeek-R1 。
DeepSeek-V3是我们与DeepSeek应用交互时使用的默认模型。这是一种多功能的大型语言模型(LLM),它是可以处理各种任务的通用工具。

DeepSeek-R1是一种强大的推理模型,用于解决需要高级推理和解决问题的任务。它非常适合编码挑战,这些挑战超出了经过数千次和逻辑问题的编写代码。

使DeepSeek成为耀眼的名声的原因是用于提高效率并补偿NVIDIA的GPU和集体通信库(NCCL)的绩效提高的数学技巧。
简而言之,DeepSeek使用智能数学来避免使用昂贵的HW,例如NVIDIA的H100 GPU来训练大型数据集。还影响了如何运行和使用模型,因此我们可以在正常(无GPU)计算功率的本地服务器上运行它。
1。低级别近似值以进行更快的计算DeepSeek的关键优化之一是低级矩阵近似值,它减少了矩阵乘法中所需的操作数量。这些方法没有执行全级矩阵乘法,而是近似具有较低维表示的矩阵,从而大大降低了计算成本。
2。分组查询注意(GQA)以节省内存GQA重组了在变压器模型中如何计算注意力的方式,从而减少了注意操作所需的记忆带宽。 GQA并没有分别计算每个查询的注意力,而是允许多个查询共享相同的键值对,从而导致: – 降低记忆消耗 – 更快的推理速度 – 减少冗余计算
3。速度和效率的混合精确培训DeepSeek使用混合精液训练,其中计算使用FP16/BF16而不是FP32,从而减少了内存足迹和加速训练。但是,为了保持数值稳定性,应用了损耗缩放技术,以确保由于精确截断而不会丢失小梯度。
4。降低计算复杂性的量化除了混合精液之外,DeepSeek还受益于量化,在量化中,使用较低的精度代表张量(例如,INT8)。这允许更快的矩阵乘法并减少存储器带宽消耗,从而提高训练效率。
5。随机舍入以保持准确性当使用较低精确的浮点格式时,使用随机舍入来减轻舍入误差的积累,尽管使用降低了精确度,但该模型仍保持高精度。
DeepSeek的数学优化允许使用最低HW上的服务器/PC上运行的更便宜的培训和更轻的型号。
根据用例和要求,运行大型语言模型(LLM)在本地提供了几个优点。以下是有人选择在本地运行LLM的一些关键原因:
1。数据隐私和安全性敏感数据:处理机密或敏感信息(例如医疗,法律或专有业务数据)时,在本地运行该模型可确保数据永远不会离开您的环境,从而降低暴露或违规的风险。合规性:本地部署可以帮助满足监管要求(例如GDPR,HIPAA),该要求授权数据保留本地。 2。控制和自定义完全控制:在本地运行LLM,可让您完全控制模型,其配置以及其运行的基础架构。自定义:您可以微调或修改模型以更好地适合特定需求,而基于云的API可能是不可能或具有成本效益的。 3。成本效率降低的API成本:基于云的LLM服务通常会根据使用(例如,每个令牌或API调用)收费。在本地运行该模型可能对大量或连续使用更具成本效益。无订阅费:本地部署避免了与基于云的LLM服务相关的重复订阅费用。 4。性能和潜伏期较低的延迟:本地部署消除了网络延迟,这对于实时应用程序或低响应时间至关重要时尤为重要。可预测的性能:您可以优化硬件和软件堆栈以确保稳定的性能,而不会受到诸如云服务中断或节流诸如外部因素的影响。 5。离线可访问性没有Internet依赖性:在本地运行该模型允许您在没有可靠的Internet访问的环境中使用它,例如远程位置或安全的设施。灾难恢复:本地部署可确保即使在Internet中断或云服务中断期间,该模型仍然可以访问。 6。透明和调试模型透明度:在本地运行该模型允许您检查其行为,输出和中间步骤,这对于调试或理解其决策过程至关重要。错误分析:当模型在您的控制之下时,您可以更有效地记录和分析错误或意外输出。 7。长期可持续性避免供应商锁定:通过本地运行该模型,您不依赖于特定的云提供商或服务,从而降低了供应商锁定的风险。未来防止:本地部署可确保即使云服务更改其定价,术语或停止服务,也可以继续使用该模型。 8。研发研究人员和开发人员可以尝试使用模型的架构,培训数据或微调过程,而无需限制云提供商。
您可以通过多种方式在本地运行DeepSeek。作为K8和容器的粉丝,我选择了容器的方式。
在这里,我在Kubernetes群集上本地运行DeepSeek-R1模型。该集群正在运行在个人笔记本电脑上的VM上。有人可能会说,这种设置并不是真正正确的气概设置,但是可以直接在baremetal上使用相同的K8S配置。就我而言,为了方便起见,我将其运行在VM内。
设置规格: 1 VM,带32G 内存和16核 /英特尔I9–9880H CPU @ 2.30GHz。没有使用GPU。分配给VM的50 GB存储。 Ubuntu 22.04.5 Lts。 Minikube K8S。 DeepSeek-R1具有70亿参数(Ollama Docker Image)。打开Web UI。实际步骤:1-安装您可以使用的任何K8S发行版。在这里,我正在使用Minikube K8,并为群集分配14个VCPU和28GB内存。
Minikube开始-CPU = 14-内存= 286722-准备任何类型(静态或动态)的K8持续量(PVS),因为后来将被2个PersistentVolumeClaim(PVC)消耗。
注意:如果您使用的是Minikube K8,则可以简单地使用Storage-Provisioner-Gluster插件,如下所示
3-转到https://ollama.com/ ,然后选择您想要的模型。在这里,我正在选择具有140亿参数的DeepSeek-R1。根据您的机器资源选择更少的参数模型。
4-进行运行的K8设置后,通过Kubectl运行以下YAML配置。它将下载并运行图像:
DeepSeek-R1 14B型号。开放式webui。它还将准备所需的卷,并通过端口11434暴露开放式GUI与模型相互作用。
--- apiversion:v1 KIND:PersistentVolumeclaim元数据:名称:开放式存储规格: AccessModes: - ReadWriteOnce资源:请求:存储:1GI --- apiversion:v1 KIND:PersistentVolumeclaim元数据:名称:Ollama-Storagory规格: AccessModes: - ReadWriteOnce资源:请求:存储:5GI --- apiversion:应用程序/V1类型:部署元数据:名称:开放式webui规格:复制品:1选择器: MatchLabels:应用程序:开放式Webui模板:元数据:标签:应用程序:开放式Webui规格:容器: - 名称:Open-Webui图片:ghcr.io/open-webui/open-webui:latest env: - 名称:ollama_base_url价值:“ http://127.0.0.1:11434”数量: -MountPath:/app/backend/data名称:开放式存储卷: - 名称:Open-Webui存储persistentvolumeclaim:索赔名称:Open-Webui存储--- apiversion:应用程序/V1类型:部署元数据:名称:ollama规格:复制品:1选择器: MatchLabels:应用:ollama模板:元数据:标签:应用:ollama规格:容器: - 名称:Ollama图片:Ollama/Ollama:最新数量: -MountPath: /root/.ollama名称:Ollama-Storagory卷: - 名称:Ollama-Storagory persistentvolumeclaim:索赔名称:Ollama-Storagory --- apiversion:批次/V1善良:工作元数据:名称:Ollama-Pull-llama规格:模板:规格: restartpolicy:永远不会容器: - 名称:Ollama-Pull-llama图片:Ollama/Ollama:最新命令:[“/bin/sh”,“ -c”,“睡眠3; ollama_host = 127.0.0.1:11434 ollama ollama luck deepseek-r1:14b”]数量: -MountPath: /root/.ollama名称:Ollama-Storagory卷: - 名称:Ollama-Storagory persistentvolumeclaim:索赔名称:Ollama-Storagory根据您的Internet连接,将需要大约2分钟的时间才能拉出所有必需的图像(〜4.5GB)并将其运行在K8S群集上。
注意:在开始使用模型之前,Ollama拉工作必须处于完整状态。所有其他POD必须处于运行状态。
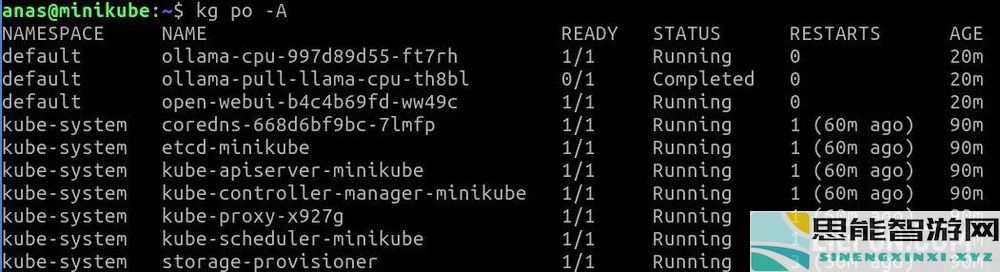
现在,我们已经有一个本地准备就绪的设置,包括运行型号,其存储空间和裸露的端口。让我们开始测试:
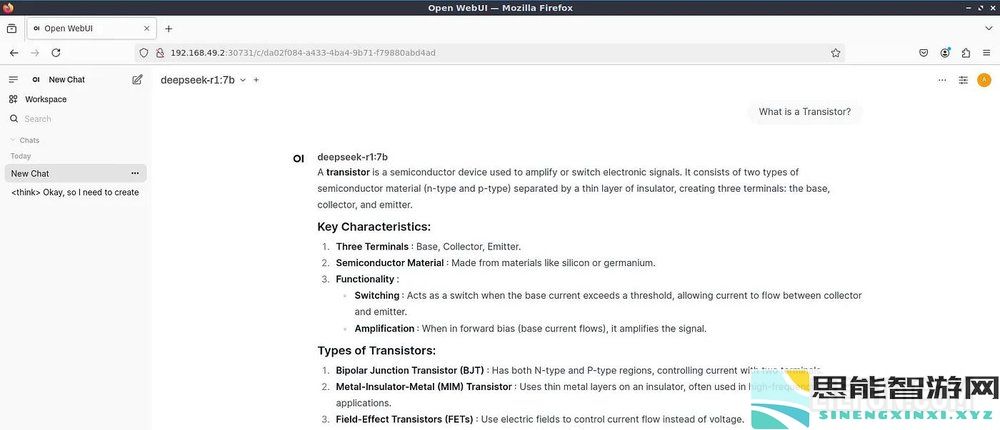
第一个问题:什么是晶体管?思考和写答案大约需要大约50秒
 第二个问题:名称(ANA)中有多少(a)字母?
第二个问题:名称(ANA)中有多少(a)字母?一些模型在此类问题上挣扎。在我的DeepSeek-R1本地设置中,大约需要大约80秒钟才能正确思考和回答。

以下是我的Linux VM的快照,所有分配的CPU都疯狂地试图在回答问题时运行该模型。

愉快的学习!
最新思能攻略
更多- 豆包、夸克与元宝,三大AI巨头各展所长,争夺市场霸主地位
- 让简洁的词汇组合形成有深度的语言表达
- 苹果AI功能再度推迟发布,Apple Intelligence为何依旧值得引起我们的关注?
- 揭示AI保护措施下的隐秘风险:有效规避对抗象征化的策略和方法
- 科技巨头加码TinyML,端侧与边缘人工智能发展进入新阶段
- 老阿姨高清免费观看电视剧:探索游戏世界的乐趣与挑战,发掘虚拟冒险的无限可能
- 变形金刚2重装上阵汽车人与霸天虎的精彩对决全程图文解析
- 苹果推出iOS 18.4 beta 2版本:iPhone现已全面支持5G-A技术
- OpenAI顶级模型曝出丑闻,CoT撰写作弊 confession,偷天换日被当场识破
- 车顶装饰条破损奔驰车主索求赔偿:AI系统评估高达51万元
- 阿里开启2025年“反内卷”新篇章:春节后推出免费“AI数字员工”服务
- 光遇染料的位置解析-全地图染料分布详细介绍
- 金铲铲之战六费单位三颗星合成方法揭秘-了解3星6费的合成规则
- 无限暖暖蓝眼泪的具体位置在哪里-详细指南与获取方式分享
- iPhone 17 Air 最新泄密消息:厚度低于6mm、搭载苹果无线芯片、全新设计的单镜头相机
最新思能智能
更多- 探秘OpenAI的最新动态与八卦内幕揭秘.pdf
- 分享英雄联盟赤金秘宝的入口位置与详细攻略
- 父母儿女一家狂第八集:围绕游戏的家庭挑战与欢乐互动,玩转亲子关系的全新体验
- 幻兽帕鲁天坠之地新版本油田具体位置在哪里?
- 逆水寒手游焚香祭故人玩法指南-焚香祭故人奇遇的详细完成步骤
- 苹果新机型iPhone 17 Air仅5.5mm厚度 将正式替代Plus系列智能手机
- 无花果转变为功能:AI驱动Anima操场的迭代之旅
- jm漫画网页版入门:探索全新游戏世界的乐趣与挑战,体验激情四溢的虚拟冒险之旅
- 燕云十六声一日千里任务的完整攻略及步骤详解
- 燕云十六声的定情信物获取方法及具体途径详解
- 诛仙世界新手开荒指南-第一天玩法技巧与推荐
- 金铲铲之战的利息计算算法及其规则详细说明
- 王者荣耀空空儿最佳装备组合解析,助你轻松上分!
- 2025年Blast赏金赛详细赛程一览|赛事时间与安排全解析
- 问剑长生中的仙玉使用技巧及其多种用途详细介绍
