


文章详情
我是 Weights & Biases 的联合创始人兼首席技术官。在过去的几个月里,我一直在测试我们的工具并构建自主编程代理。我制作了一个基于 ...
2025-04-04 04:35:03
文章详情介绍
我是 Weights & Biases 的联合创始人兼首席技术官。在过去的几个月里,我一直在测试我们的工具并构建自主编程代理。
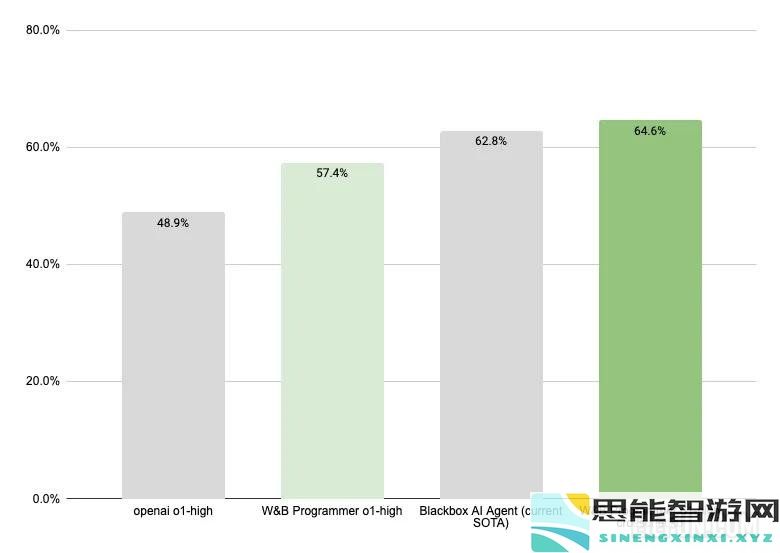
我制作了一个基于 OpenAI o1 的 AI 编程代理,它现在在 SWE-Bench-Verified 上是最先进的!它解决了 64.6% 的问题。为此,我大量使用了用于 AI 应用程序的 Weave 工具包,了解了大量有关 o1 的知识,并在此过程中构建了许多新东西。
如果您不熟悉,SWE-Bench-Verified 是软件工程代理现有的最佳基准。它包含 500 个 github 问题、docker 镜像和单元测试。典型的代理像人类程序员一样在 Docker 容器内自主运行,迭代地读取和编写代码并进行测试,直到他们认为问题已解决。
我们的解决方案是我们所知的第一个基于 o1 的代理,它在 SWE-Bench Verified 排行榜上名列前茅。这也是对 OpenAI 发布的 o1 结果的重大改进,该结果使用了基本的代理框架。
请继续阅读,了解我是如何获得这一分数的、与 o1 合作的经验教训,以及我们权重与偏差的发展方向。
我们的 SWE-Bench-Verified 代理使用:
o1 对于所有代理步骤和编辑逻辑,reasoning_mode 高基于 gpt4o 的内存组件,用于压缩代理的步骤历史记录定制的 Python 代码编辑器工具集,旨在有效地使用模型上下文能够注册在每个编辑步骤后运行的“自动命令”每个实例进行 5 次并行部署,最后使用 o1 决胜局进行“交叉检查”步骤以选择最佳部署关于该代理的工作原理,有很多内容可以分享。特别是我们新的“交叉检查”机制,用于通过算法选择 N 个代理中最好的一个,效果非常好,并且可能有些新颖。但这将是另一天的故事。
o1 本身就是一个令人难以置信的模型。与之前的代币完成模型相比,这是一个非常不同的模型。
o1 在查明大块代码上下文中的错误方面比之前的模型更好。它更擅长完全按照你告诉它的去做。通过阅读数千条痕迹可以清楚地看出,O1 较少依赖于这些 Github 存储库的先验知识,而更多地依赖于“思考”问题。
o1 照你说的做您可以在提示中添加更多详细信息,o1 会遵循它。例如,这是我提交的主要提示的一部分:
重要的测试脚本说明: - 如果问题已解决,则必须以状态 0 退出;如果问题未解决,则必须以非零退出代码退出- 必须将逐步输出打印到控制台- 必须将断言中使用的完整值打印到控制台,或将它们记录到文件中。 - 您必须手动检查测试脚本的输出以确认其按预期工作。 - 您必须手动检查断言中使用的打印或记录的值以确认它们是正确的。 - 糟糕的测试脚本会导致糟糕的结果!确保您的断言尽可能窄,并且该值实际上是您的测试脚本所期望的。这是提示的完整任务说明部分 58 行中的 7 行。每一项都是通过不断地进行评估和审查大量代理轨迹来辛苦获得的。
o1 的不同之处在于它实际上尊重所有这些,几乎所有时候。在使用以前的模型时,我有一种挥之不去的感觉,即在提示中再添加一行可能会开始降低模型遵守提示其余部分的能力。 o1 的情况却并非如此。
以结果为导向的提示正如其他人指出的那样,告诉 o1 你想要的结果是什么,并给它空间来弄清楚如何实现该结果将为你带来最好的结果。
这是声明我们想要的结果的提示部分:
仅当满足以下条件时才调用 task_done: - 您对问题的正确修复位于观察消息中“您的修改”下的 diff_observation 中- 最近运行的测试脚本退出为零,这意味着问题已解决- 你已经证明你的测试脚本在头部以非零值退出- 您已成功运行现有单元测试并检查了输出- 任何剩余的现有单元测试失败也会失败这本质上是代理的停止条件。 o1 非常擅长迭代,直到上述所有条件都成立。
事件时间顺序混乱对于使用 o1 作为代理驱动程序来说,这是一个非常重要的因素:它并不总是正确地推理事件的时间顺序。
作为示例,请考虑以下代理操作序列:
对文件进行首次编辑运行失败的单元测试对文件进行第二次编辑有时,在这样的序列之后,代理会说类似“我编辑了代码来执行 X,但单元测试仍然失败”,而在第二次编辑后没有实际运行测试。
我解决这个问题的解决方案是减少代理推理按时间排序的事件的需要。 “自动命令”工具允许代理注册命令以在每次文件修改后运行。
o1 非常擅长按照你所说的去做,我认为你实际上可以通过说“按顺序回顾你之前采取的每一步,建立你对世界当前状态的了解”来指示它正确地安排事件的时间顺序随你走”。不过,目前这样的提示会更频繁地触发 OpenAI 的无效提示检测逻辑,因此我没有花很多时间在这种方法上。
我很高兴看到有人围绕这个概念进行评估!
我想解决这个问题的原因之一是证明我们在 W&B 所持有的信念:最好的工具可以带来最好的结果。如果这是真的,那么我们应该能够使用我们自己的工具获得世界一流的结果。我们有。
在过去的两个月里,我们进行了大量的迭代和分析,才让这个代理运行得如此顺利。
W&B 编织Weave 是我们用于开发人工智能应用程序的工具包。我使用 Weave 来跟踪我所做的一切,并使用 Weave 的评估框架来进行我运行的所有实验。事实上,在实现这个解决方案的过程中,我运行了 977 次评估。
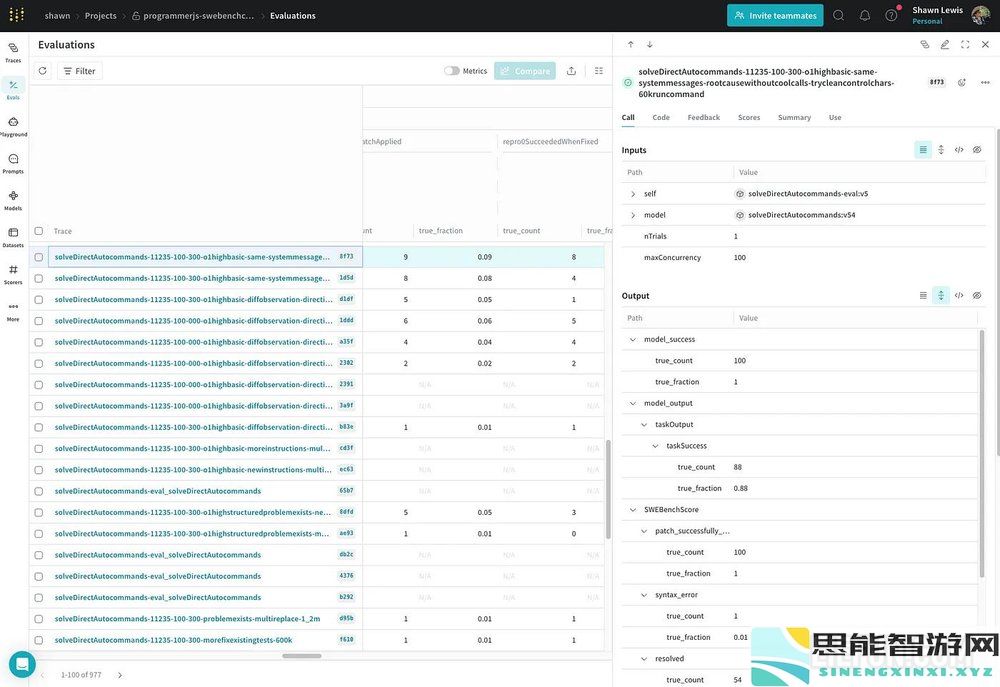
当我做这项工作时,Weave 本身得到了很大的改进。特别是新的游乐场为测试同一提示的多个试验提供一流的支持,这是无价的。
评估工作室在此过程中,我构建了一些新工具,这些工具现在构成了我们目前所说的“Eval Studio”。该工具完全由 Weave 数据支持,它没有自己的服务器组件。
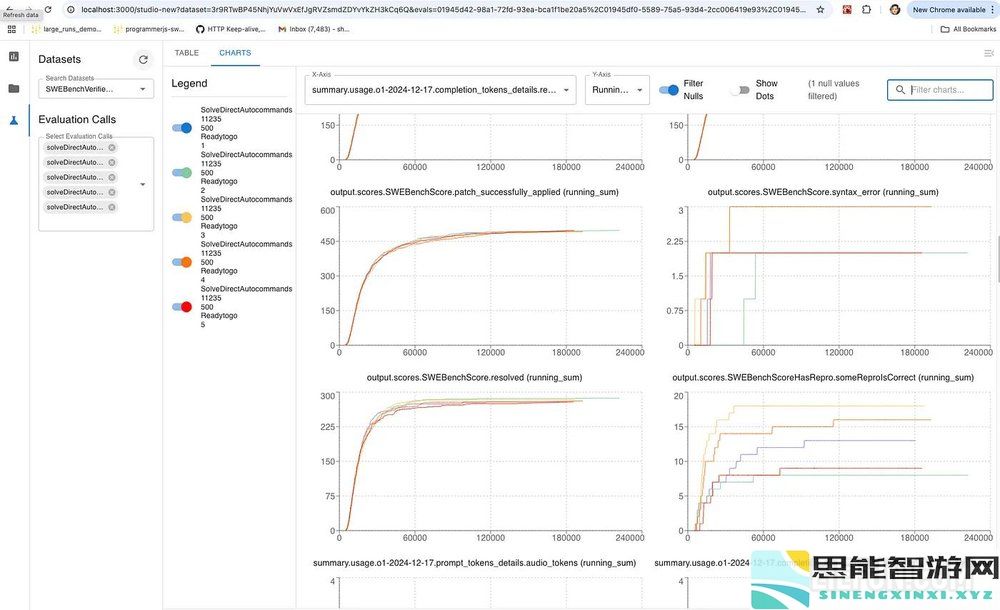
此图表视图对于观看实时运行和深入统计结果非常有用。
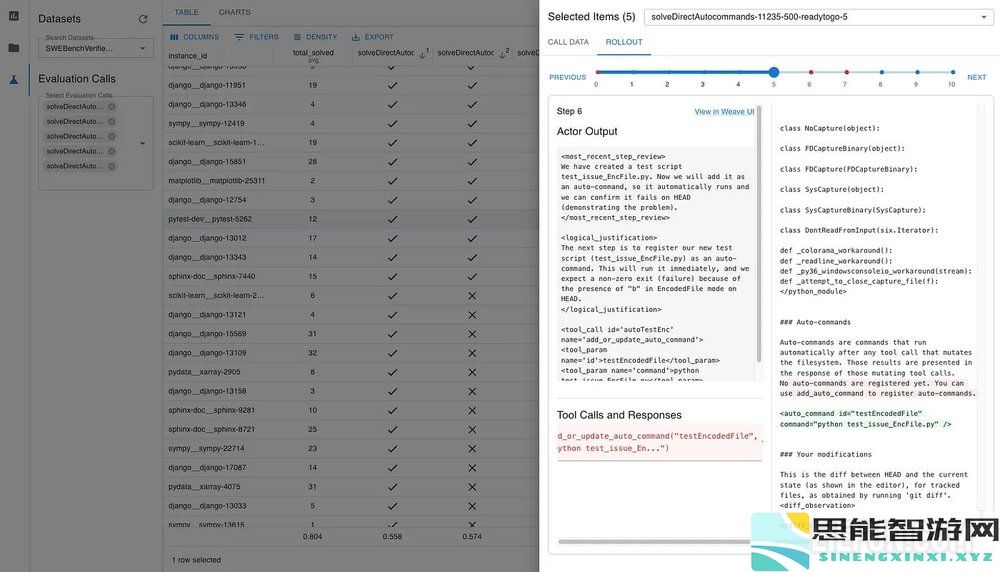
我在表格视图和卷展栏抽屉中花费了大量时间,以了解新模型比以前的模型表现更差或更好的情况。
Eval Studio 概念将在接下来的几个月内融入 Weave,我们还有更多这些概念的来源。我相信,做到这一点将推动包括人工智能安全在内的各种应用取得进展。
相移Phaseshift 是一个用于编写 AI 代理的新框架。我用打字稿编写它,因为它强大的类型系统可以帮助我推理接口和组合。
Phaseshift 是围绕 Weave 的核心概念构建的。这意味着您可以同时获得数据和代码的版本控制等内容,这样您就可以找出迭代时更改的内容。没有其他工具可以做到这一点:
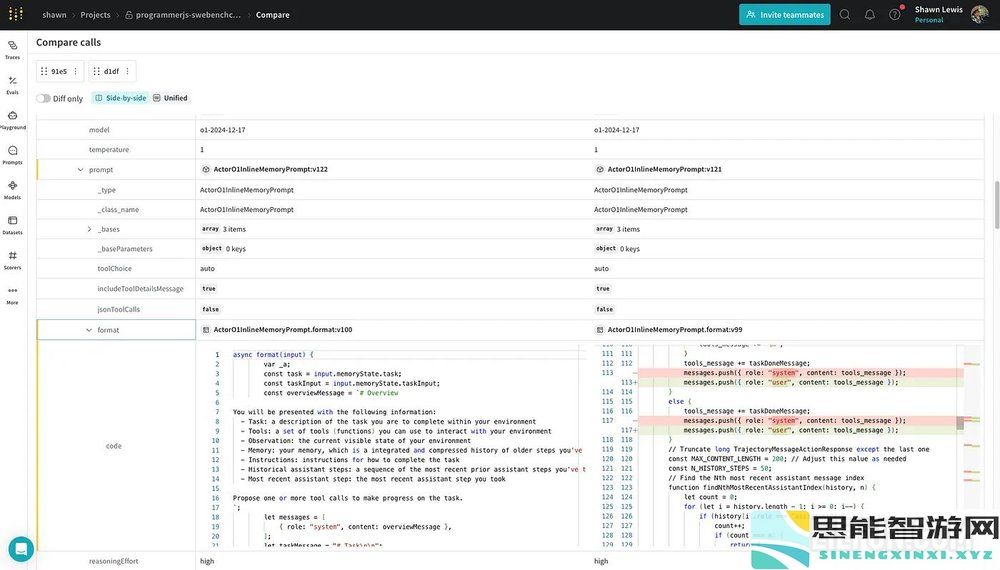 在 Weave UI 中区分两个相移代理。
在 Weave UI 中区分两个相移代理。它将 Weave 的评估概念融入到您可以编写的任何函数或管道中作为一等公民。
我很高兴能够完善相移并在有机会时发布它!
我们对自己在人工智能编程前沿的竞争能力感到非常兴奋,我们希望帮助我们的客户利用这些能力更快地构建。
我们也喜欢构建世界一流的工具,并且我们很高兴能够提供沿着这条道路开发的所有新工具。
目前,我们正在将官方的 SWE-Bench 验证提交内容放在一起,我们很高兴能够进一步推进这一领域。
在 X 上关注我,了解我们的工具和人工智能编程进展的更新!
最新思能攻略
更多- GTC 2025:NVIDIA通过DGX Spark和DGX Station台式机进军人工智能个人计算机市场
- 真三国无双起源中的全收集挑战解析-全面总结难点及应对策略
- 首次尝试,六位参与者在七天内的真人秀体验!南洋理工等机构发布首个视角AI生活助理数据EgoLife
- 人工智能助力设计师克服冒名顶替综合症增强自信心的有效方法
- 绝区零1.5版本新增加的称号详细汇总-全新称号一览及获取方式
- 英雄联盟恶魔手契印记解锁方法详细指南与技巧分享
- 如何获取王者荣耀与QQ飞车的联动皮肤以及详细介绍
- 小辣椒3美国伦理:探索伦理选择对玩家游戏体验的深远影响与角色塑造
- 仅需不到1美元,香港大学三位学者开源全球第三强AI助手Deep Research
- cf2025年2月最新kol兑换码查询-2025年2月kol邀请码完整一览
- 炉石传说2024年世界总决赛各大卡组代码汇总与分析
- 怪物猎人荒野中两大怪物对决任务详细完成步骤解析
- Nvidia 计划大幅降低 AI 模型费用,以促进技术普及和应用
- 如龙0金钱岛回收利润详解及购买物品的具体位置指南
- 国内竟然拥有全球最大AI竞技场?五大热门国产模型化身武侠少女进行精彩对决
最新思能智能
更多- Nat. Biomed. Eng. | 利用多模态人工智能技术提升乳腺癌的精准诊断能力
- apex24赛季武器平衡调整详细说明与影响分析
- 美国向马来西亚施压,要求修复贸易漏洞以防止数十亿美元NVIDIA AI芯片流向中国
- 告别OpenAI,Figure发布首个VLA模型:人形机器人即将迎来 iPhone4 的革命性时刻?
- 谷歌Chrome面临出售压力,AI技术是否将彻底取代传统浏览器?
- 燕云十六声射覆答案2025全解析-燕云十六声射覆题库详细介绍与汇总
- 2025年英雄联盟LPL春季赛完整赛程及最终比赛结果揭晓
- Palantir对白宫科学技术政策办公室(OSTP)提出的AI战略行动计划作出的反馈与回应
- 天国拯救2特罗斯基恶魔支线任务详细攻略与通关步骤
- 手腕上的智能助手:Apple Watch 将实现视觉识别和理解你的日常需求
- 老公牛影院免费观看电视剧的优点:畅享无广告的观影体验,让人沉浸在精彩的剧情中
- 鸣潮必胜客的联动活动2025年——详解鸣潮与必胜客的合作内容
- 和平精英俏喵蜜语特效效果评测-详细展示俏喵蜜语特效魅力
- 基金公司发布新策略,突破性发展与AI技术息息相关
- 光遇森灵日活动详细玩法介绍与参与指南
